







")
Data Science and Machine Learning - #41 Projeto Completo (Testando Vários Algorítimos)
23/06/2022No tutorial de hoje realizaremos os testes de desempenho em vários algorítimos diferentes para verificar qual oferecer o melhor resultado para nossos dados.
Para essa aula, é necessário importar os seguintes módulos:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split, cross_val_score,GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.neighbors import KNeighborsRegressor
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error
%matplotlib inlineTestando Regressão Linear
Vamos iniciar realizando o teste com o algorítimo de regressão linear:
params = [
{
'fit_intercept':[True,False],
'normalize':[True,False],
'copy_X':[True,False],
'positive':[True,False],
}
]
ins = LinearRegression(normalize=True)
#grid_search = GridSearchCV(ins,params,cv=10)
#grid_search.fit(X_train,y_train)
#grid_search.best_params_
ins.fit(X_train,y_train)
pred = ins.predict(X_test)
ins.score(X_test,y_test)
print('RMSE',np.sqrt(mean_squared_error(y_test,pred)))
cross = cross_val_score(ins,X_test,y_test,cv=10)
final = sum(cross) / len(cross)
finalÁrvores de Decisão
Vamos verificar a eficácia das árvores de decisão:
params = [
{
'criterion':['mse','mae'],
'max_depth':[None,2,4,8,15]
}
]
ins = DecisionTreeRegressor(max_depth=8)
#grid_search = GridSearchCV(ins,params,cv=5)
#grid_search.fit(X_train,y_train)
#grid_search.best_params_
ins.fit(X_train,y_train)
pred = ins.predict(X_test)
ins.score(X_test,y_test)
print('RMSE',np.sqrt(mean_squared_error(y_test,pred)))
cross = cross_val_score(ins,X_test,y_test,cv=10)
final = sum(cross) / len(cross)
finalFlorestas Aleatórias
Vamos verificar a eficácia das florestas aleatórias:
params = [
{
'criterion':['mse','mae'],
'max_depth':[None,2,4,8]
}
]
ins = RandomForestRegressor()
#grid_search = GridSearchCV(ins,params,cv=5)
#grid_search.fit(X_train,y_train)
#grid_search.best_params_
ins.fit(X_train,y_train)
pred = ins.predict(X_test)
ins.score(X_test,y_test)
print('RMSE',np.sqrt(mean_squared_error(y_test,pred)))
cross = cross_val_score(ins,X_test,y_test,cv=10)
final = sum(cross) / len(cross)
finalKNN
Vamos verificar a eficácia do KNN:
params = [
{
'weights':['uniform','distance'],
'n_neighbors':[2,5,10,15,20,30]
}
]
ins = KNeighborsRegressor(n_neighbors=10, weights='distance')
#grid_search = GridSearchCV(ins,params,cv=5)
#grid_search.fit(X_train,y_train)
#grid_search.best_params_
ins.fit(X_train,y_train)
pred = ins.predict(X_test)
ins.score(X_test,y_test)
print('RMSE',np.sqrt(mean_squared_error(y_test,pred)))
cross = cross_val_score(ins,X_test,y_test,cv=10)
final = sum(cross) / len(cross)
finalSVM
Vamos verificar a eficácia do SVM:
params = [
{
'C':[0.1,1,10],
'gamma':[0.1,1,10]
}
]
ins = SVR()
#grid_search = GridSearchCV(ins,params,cv=5)
#grid_search.fit(X_train,y_train)
#grid_search.best_params_
ins.fit(X_train,y_train)
pred = ins.predict(X_test)
ins.score(X_test,y_test)
print('RMSE',np.sqrt(mean_squared_error(y_test,pred)))
cross = cross_val_score(ins,X_test,y_test,cv=10)
final = sum(cross) / len(cross)
finalResultado dos Testes
Ao fim dos testes, chegamos ao seguinte resultado:
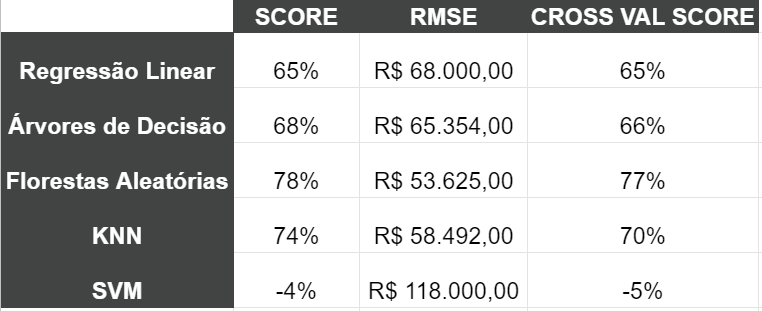
Por hoje é só! Sucesso nos códigos e na vida!


Posts Relacionados
Data Science and Machine Learning - #40 Projeto Completo (Dados de Treino e Teste)
Na aula de hoje aprenderemos como separar os nossos dados em dados de teste e treino no aprendizado de máquina.

Data Science and Machine Learning - #42 Projeto Completo (Dados Reais)
No tutorial de hoje vamos testar como realizar a compra de um imóvel que irá se valorizar a Califórnia utilizando o melhor modelo de algorítimo.
Python
Nesta seção aprofundaremos os conhecimentos sobre uma das linguagens em maior ascenção no mercado, o Python.