








Data Science and Machine Learning - #32 KNN I
01/01/2022Na aula de hoje aprenderemos um novo algorítimo de Machine Learning, conhecido com KNN ou K vizinhos mais próximos.
KNN no Machine Learning
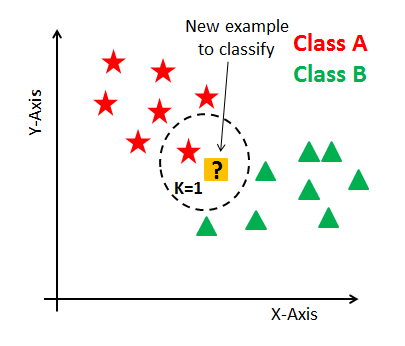
O hiperparâmetro k tem forte importância no KNN e representa a quantidade de vizinhos que você quer comparar a sua classe.
Veja um exemplo abaixo:
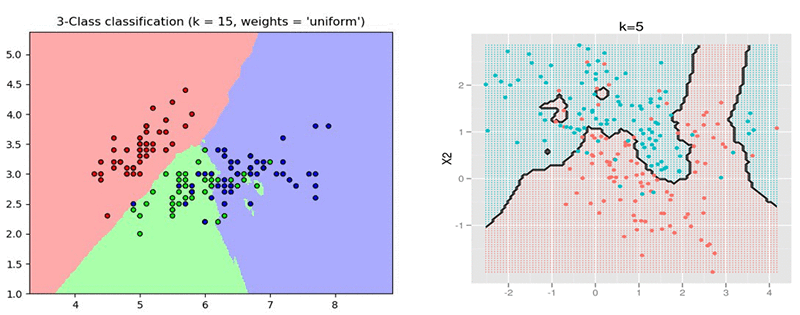
Da mesma forma veja este outro exemplo:
Repare que dependendo do k escolhido a classificação pode ser bem diferente.
Importando módulos
Vamos importar os módulos necessários para rodar a nossa análise:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split, GridSearchCV,cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report, confusion_matrix
%matplotlib inlineImportando DataFrame
Neste exemplo vamos classificar um câncer como benigno ou maligno de acordo com as características da pele, sangue e outras características. Para baixar o dataset clique aqui.
df = pd.read_csv("cancer.csv")
df.head()Preparando os dados
Vamos excluir colunas desnecessárias, transformar dados string em dados binários e limpar dados vazios para preparar nossos dados para o aprendizado de máquina:
del df["id"]
del df["Unnamed: 32"]
df['diagnosis'].unique()
idCat, cat = pd.factorize(df['diagnosis'])
idCat
#M = 0 B = 1
df['diagnosisCat']=idCatAnálise exploratória
Vamos analisar os nossos dados e a integração entre eles:
df.info()
df.describe()
sns.countplot(x='diagnosisCat',data=df)
df['diagnosisCat'].value_counts()Por hoje é só! Sucesso nos códigos e na vida!


Posts Relacionados
